Openrouter Fusion API
Posted by tdchaitanya 2 days ago
Comments
Comment by dsl 2 days ago
After extensive testing and benchmarking I discovered that when you ask one model to judge another's response you don't actually get a better answer. You are just asking it "how closely does this resemble the answer you would have given me." Additional rounds and all the "obvious" solutions that pop into your mind reading the proceeding sentence are essentially just cranking up the temperature.
I did find a solution, but it is insanely expensive. Maybe if this gains traction I'll release mine.
Comment by comboy 1 day ago
I'll share a revelation which vastly improved my results: tell judges to evaluate truth and usefulness/should-be-fixed axis separately. Because inevitably with a prompt that is forcing to find issues you will end up with nitpicks. Plus truth axis allows to better evaluate the issue-finder models for your use case.
That's some part of what happens when I generate explanations like this one: https://hanzirama.com/character/%E6%9D%A5#explain - at this point the site is a small side product of my LLMs-evaluation machinery.
Bonus content for patient readers: if you need top quality you will likely need to pin provider(s) on OR, :exacto is not enough to get good repeatable results especially for open-weights models.
Comment by SubiculumCode 1 day ago
Anyone else fell like if you can trick the LLM into a mode where it "feels" superior, it will act the asshole very well?
Comment by fridder 1 day ago
Comment by SubiculumCode 1 day ago
Comment by ceroxylon 1 day ago
Comment by fomoz 1 day ago
I have tested two judge models in my apps:
1. Judge model for a resume tailor. It evaluated the result resume vs the base resume and JD and judged it out of 10 on fit and honesty. It worked well and was useful.
2. Review model in my LLM trading bot platform. It reviews decisions from the Main model. The problem here is that the bot is navigating ambiguity. So unless the Review model catches an outright blunder (e.g. making a decision on wrong candle price or a BUY when it should be a SELL), the Review model can do more harm than good.
First, it adds latency to decisions, decisions take twice the amount of time (like be 60s instead of 30s for Gemma 4 31B). Second, it can make the bot too cautious, because Review model only runs on BUY/SELL decisions and not HOLD decisions, so the bot will only make less trades instead of review model increasing number of trades (because of latency and cost).
So overall, I think you'll get better results with a better model single shotting it rather than a review model if the answer isn't easily verifiable. But then why do you need a judge model and not just have the same agent review itself?
ALSO, if you read the reasoning text for a reasoning model (like Gemma 4), you see that it ALREADY reviews itself. So it's doing its best, re-review isn't really adding information. It's an interesting experiment, but you need to evaluate on a case by case basis.
Comment by r0fl 22 hours ago
I’ll have codex write a detailed prd.md file of how my project works, logic, goals, tech stack etc
Then I’ll use openrouter to have multiple models analyze that file, and write me a new improvements.md file
Then I’ll have codex check all those improvements md files and implement what it thinks are the best things that were missing
It’s quick, not expensive, and usually finds things I would have never thought of on my own
Comment by ggrantrowberry 18 hours ago
Comment by r0fl 17 hours ago
Comment by WhitneyLand 1 day ago
Comment by awongh 1 day ago
I don't think it would work without a human in the loop but it is surprising to me how varied models' vibes are and how a system design varies by what it thinks is important to include and emphasize.
Comment by zone411 1 day ago
Comment by bilater 1 day ago
I think there is alpha just have to be very careful how you let the models com up with solutions and collaborate.
Comment by efromvt 1 day ago
Comment by bushido 1 day ago
Here's what I use: https://github.com/DheerG/swarms
Comment by sfilkin 1 day ago
Comment by jiaosdjf 1 day ago
Comment by dist-epoch 1 day ago
I regularly ask both GPT and Gemini to give me options - programming libraries to do X, architecture suggestions, names for projects/services/classes
After they answer I ask each model what does it think of the other answer, and to give me a final suggestion considering both answers.
Both GPT and Gemini would frequently say "that other answer is much better than my one, it considered X factor that I missed".
Comment by SubiculumCode 1 day ago
Comment by fjwood69 15 hours ago
Comment by huflungdung 1 day ago
Comment by crooked-v 1 day ago
Comment by all2 1 day ago
Let's review <filepath or specific file> for architectural issues. Spawn 10 agents, create personas for them, have them review the _api.go and write their review to reviews/<persona>-review.md, then have each agent do a round robin response to 3 of the reviews of their choosing (based on the abstract at the beginning of each review) and write the response to response/<original file name>-<agent persona name>-response.md. Then we do rebuttals to the responses in rebuttals/<response file name>-rebuttal.md. Finally, each agent should launch agents to review the reviews, responses, and rebuttals to their review, and compile findings to findings/<original file name>-findings.md. Finally, have another agent compile the findings and write that to review-findings.md. Present a concise version of the findings here.
Comment by daheza 1 day ago
Do you review all the files that are generated to ensure there's no hallucinations? Do you just review the last file of concise findings instead?
Is the intent here that the hallucinations will be countered by running through multiple agents that you end up with only the truth? Have you seen anything in the last version that was egregiously wrong?
I was worried about the cost but if you are using local hosted models, then I suppose you don't need to deal with that as much. Locally hosted models still have issues running commands locally and reaching out to the internet right? So this is all just them running with the context of the file, without reference tot he rest of the project?
Thanks for any responses to this.
Comment by all2 1 day ago
Sometimes, yes. Typically I'll read the final fusion doc, and then trace backwards if there is something that looks relevant. Sometimes I'll read all the abstracts as they come through.
> Is the intent here that the hallucinations will be countered by running through multiple agents that you end up with only the truth? Have you seen anything in the last version that was egregiously wrong?
The intent isn't so much avoiding hallucinations, rather I was attempting to acquire unique, domain specific insight. My read-through of the final doc is a 'pick and choose', where I weed out what isn't relevant, and keep what is. I haven't seen anything way out of whack, as agents will typically check each other and call each other out in the review/rebuttal stage.
> So this is all just them running with the context of the file, without reference tot he rest of the project?
This is run in an agent harness locally, so each reviewer has access to the whole project. The review rebuttal stage rarely sees agents re-read files, though, unless one of them is particularly aggressive and is going deep on something (GPT 5 series will do this to make a point, sometimes).
> Thanks for any responses to this.
No worries. This is pretty easy to try, even with something you don't own. You can run it in any harness that allows spawning sub-agents.
If there's a lot of interest, I could spin up a simple web app that does this just so folks can see it churn on a target git repo or project files or whatever.
Comment by kristjansson 1 day ago
Comment by all2 1 day ago
This is based on earlier work from late '25 where people were doing similar things. My added bit is the 'unique identities'. What I found was that the root agent typically picks identities relevant to the project, and so you get relevant 'data' or 'views' from a variety of angles.
Comment by andai 2 days ago
Surpassing Frontier Performance with Fusion
https://news.ycombinator.com/item?id=48525392
And a slightly better UI here: https://openrouter.ai/fusion
On OpenRouter's fusion API your request is routed to several models simultaneously and a judge model combines their answers into a final response. This significantly boosts performance, at the cost of time (at least on the one benchmark they tested, a deep research benchmark).
They have a Budget preset consisting of 3 cheaper models (which roughly matches Fable on that benchmark, costing half as much), and a Quality preset of 3 expensive ones (which beats Fable, but costs twice as much as Fable).
Pareto graph: https://openrouter.ai/blog/images/blog/fusion-benchmark-cost...
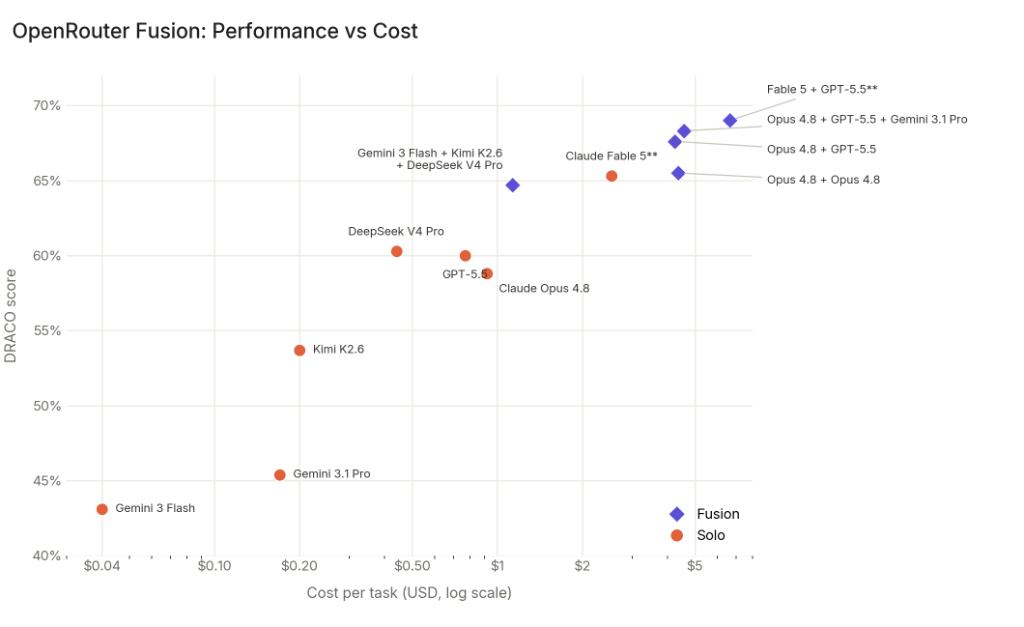{kind=link}
Curiously, fusing a model with itself also boosted performance (2xOpus4.8 roughly matching Fable on the benchmark, but costing twice as much as Fable). There's a further, smaller gain from mixing different models. The main gain seems to be from additional test time compute.
Would love to see more research on this, especially focusing on the cheap models that came out recently (e.g. Fusing DSV4 with itself, or with Mimo), and to see what the tradeoffs look like between running a fusion (parallel test time compute) vs increased reasoning or turns.
Comment by wongarsu 2 days ago
Back in the GPT2 to GPT3 era this was a pretty common thing to do. You are effectively taking more samples from the space of likely outputs. If your model can do the task 60% of the time just take 5-10 samples and implement some kind of majority voting
It became less common to use as models got high accuracy on problems where combining results is trivial. But with a more complex judge (a competent LLM) you can still get better results by just sampling more of the output space and picking out the best aspects
Comment by sigmoid10 2 days ago
Comment by waysa 2 days ago
I wouldn't be surprised if Fable/Mythos is a model distilled from a Panel/Council of Claude instances. Recursive self improvement is something all AI labs must be working on in some way or another.
Comment by qsort 2 days ago
Comment by andai 1 day ago
That definitely doesn't sound right.
Comment by andai 1 day ago
I'm not seeing that? Did you maybe misread the #2 ranked one as Fable + GPT + Gemini? It's actually Opus + GPT + Gemini.
Comment by jorvi 2 days ago
Comment by andai 1 day ago
If it can do it, but unreliably, that's where you would get major gains from iterating. I think the Chinese models are in that sweet spot, for many tasks. I would love to test that.
I started working on my own fusion system yesterday. I'm not sure how to benchmark it though.
The thing I'm most interested in is reliability. Going from 90% to 95% on a benchmark doesn't seem like much but you've cut the error rate in half.
Comment by Garlef 2 days ago
Out of interest: Was this still before CoT/thinking-mode became the norm?
Comment by awllau 1 day ago
Comment by michaelbuckbee 2 days ago
As expected, Fusion was 7x slower and 4x the cost.
This isn't a knock against it, just that it I think this places Fusion into a "use it only when you need it" category.
Comment by nielsole 2 days ago
Comment by IanCal 2 days ago
The idea would be to use fusion with simpler, cheaper models.
Comment by awllau 1 day ago
Comment by galsapir 1 day ago
Comment by jimmypk 1 day ago
Comment by alex7o 1 day ago
Comment by arizen 2 days ago
It felt, like Fable was able to kinda grasp very deep knowledge/intelligence layers and outline solution not only in agreeable way, but rather it proposed to prioritize solution items, with discarding some of the items, which made a lot of sense to me.
While Fusion felt more like a bit diversified answer of the same class of pre-Fable SOTA models, without touching the depth of knowledge/intelligence layers, which Fable was able to get, in my very limited tests I did, while Fable was accessible.
Comment by SteveMorin 1 day ago
Built - claude-fusion-launcher — run Claude Code on a panel of models, not just one
Also shows cost
Comment by admn2 1 day ago
Comment by SteveMorin 1 day ago
Comment by ljlolel 1 day ago
Comment by lukewarm707 1 day ago
it's nice to see an actual privacy committment, i spend a lot of time reading through reams of evasive and nebulous provider terms
Comment by kgeist 1 day ago
Models seem to be trained to return nice, round numbers of items, like 5, 10, or 15 (because of interference from training on marketing materials?) Plus, recall is far from 100% on large contexts. So if your code has 27 bugs, each run may find a different set of 10 issues out of the 27, whether you use several models or call the same one repeatedly.
Comment by ElFitz 1 day ago
- multi-model consensus, with multiple cross-review rounds. Obviously, the number of inference tasks explodes with the number of models. Led to some interesting results [^0].
- giving an agent "stray thoughts" produced by the same model, or another, giving the second model a selection of the agent’s context, with different triggers (random, loop detection,…)[^1]. So far has proven very helpful and much cheaper than the first.
[0]: https://github.com/lightless-labs/refinery
[1]: https://github.com/Lightless-Labs/skunkworks/tree/main/flux
Comment by bsenftner 1 day ago
I get significantly better results by pre-prompting each LLM (they can be the same LLM too, just another instance), I pre-prompt them to approach from a different perspective. Basically, I create expert personas that each believe they are someone of a different career, different intellectual perspectives, and then that generates a real debate between experts.
Comment by andai 1 day ago
(10 points on the benchmark, or a relative increase of over 20%)
https://news.ycombinator.com/item?id=44630724
TFA on the other hand tests two things at once: mixing models, and "fuse a model with itself",! the latter being just test time compute. e.g. Opus was able to match Fable on TFA, at the cost of costing twice as much money (and presumably time).
These two dimensions are orthogonal but can be combined for further gains.
It's not clear that every task benefits from it though. The only benched deep research, and their results are a bit weird. (e.g. they have DeepSeek outranking frontier models.)
More research needed!
Comment by Oras 1 day ago
I would love to hear why they have created it, what was the business case, what this is going to serve? As you said, this is pretty easy to replicate
Comment by bsenftner 1 day ago
Comment by monkeydust 1 day ago
Repo with video: https://github.com/monkeydust/rightmind
Comment by genxy 1 day ago
Comment by andai 1 day ago
Comment by all2 1 day ago
Comment by genxy 16 hours ago
Comment by chrisss395 1 day ago
I worry its kind of like asking 2-3 different consultants what the optimal strategy is for your business...and I'm not sure merging the answers produces anything material better.
Comment by eknkc 2 days ago
Seeing this log is interesting: https://link.ekin.dev/6RzYGGX7
It came up with a decent response but I guess Opus or GPT 5.5 would do fine anyway. Gotta try it on different stuff. But this feels like it would work great on some situations.
Comment by rektlessness 2 days ago
Comment by maccam912 1 day ago
Comment by SteveMorin 1 day ago
Comment by rektlessness 1 day ago
Comment by bushido 2 days ago
I found that Fable didn't have as much of an impact when put in a team.
But it was/is a very pleasant model to work with 1:1. And was the first time I didn't use my primary team based workhorse in months, across 10s of sessions last week.
Comment by _pdp_ 1 day ago
That is more or less the same thing.
I am not sure who is the intended user of this fusion api as with all things prompt + model matter.
Comment by vidarh 1 day ago
Comment by cj 1 day ago
A unified UI would be great, although not obvious how useful the "fusion" value prop is.
Comment by predkambrij 1 day ago
Comment by Havoc 2 days ago
One scenario I can see it working is writing markdown specs before the coding starts and analysing it for gaps. That’s so few tokens that throwing as much LLM against it as possible is worthwhile regardless of cost per million tks
Comment by robertclaus 1 day ago
Comment by mischa_u 1 day ago
Comment by egeres 2 days ago
Comment by DavidCanHelp 1 day ago
Comment by kin 1 day ago
Comment by kloud 1 day ago
Comment by __mharrison__ 1 day ago
Comment by jedisct1 1 day ago
Two instances of the same model, a producer and a reviewer, and the loops doesn't end until everybody's happy.
Comment by galsapir 1 day ago
Comment by irthomasthomas 1 day ago
"I find that recently I end up using all of the models and all the time... for a lot of problems they have this 'NP Complete' nature to them, where coming up with a solution is significantly harder than verifying a candidate solution. So your best performance will come from just asking all the models, and then getting them to come to a consensus."
So to reign in the token explosion somewhat I added a simple rank mode, which produces only a ranking, and then the top ranked answer is returned. You can use this in combination with meta-consortiums like this
>llm consortium save cns-kimi -m k2.7-code -n 5 --arbiter mercury-2 --judging-method rank
llm consortium save cns-glm -m glm-5.2 -n 5 --arbiter mercury-2 --judging-method rank
llm consortium save cns-meta-glm-kimi -m cns-glm -m cns-kimi --max-iterations 1 --arbiter qwen-3.5 # judging-method left at default to create a synthesis
If you combine it with the llm-model-gateway plugin you can serve a consortium like a regular model on an openai proxy and the response will be the synthesis, and conversation context is preserved for multi-turn chats.
[0] https://x.com/karpathy/status/1870692546969735361 Further reading: Mixture-of-agents https://www.together.ai/blog/together-moa Google's Mind-Evolution https://arxiv.org/html/2501.09891v1
Comment by rusk 1 day ago
I had been trying to fill this up with big models but it doesn’t seem like these give a good return per Gb
I’m looking at that and wondering would I be better off running multiple such models in parallel. It would probably be a better way to load balance across SLI.
My guess is the scaling will be more “mythical man month” than “no more free lunch” - the interaction of models resembling social dynamics moreso than multi-core setups.
Given that these actors are largely homogenous in culture and incentivising, and coordination overhead is drastically reduced.
Commonly we consider optimal team size to be between 3 and 7 and Brookes’ maximum team size is around 10 or so before the system fails. It should be possible to blow way past those numbers and still experience increased gains in productivity as long as you can keep all your instances stoked.
Comment by ElijahLynn 1 day ago
Comment by aplomb1026 1 day ago
Comment by implexa_founder 1 day ago
Comment by insumanth 2 days ago
Comment by 64lamei 1 day ago