Unrolling the Codex agent loop
Posted by tosh 20 hours ago
Comments
Comment by postalcoder 18 hours ago
Their communication is exceptional, too. Eric Traut (of Pyright fame) is all over the issues and PRs.
Comment by vinhnx 13 hours ago
Comment by phrotoma 3 hours ago
A stand alone rust binary would be nicer than installing node.
Comment by vorticalbox 2 hours ago
> The Rust implementation is now the maintained Codex CLI and serves as the default experience
[0] https://github.com/openai/codex/tree/main/codex-rs#whats-new...
Comment by alabhyajindal 2 hours ago
Comment by redox99 17 hours ago
Comment by atonse 17 hours ago
Comment by mi_lk 17 hours ago
Comment by swores 6 hours ago
It's fair enough to decide you want to just stick with a single provider for both the tool and the models, but surely still better to have an easy change possible even if not expecting to use it.
Comment by mi_lk 4 hours ago
Comment by behnamoh 13 hours ago
Comment by consumer451 11 hours ago
How much will a synthetic mid-level dev (Opus 4.5) cost in 2028, after the VC subsidies are gone? I would imagine as much as possible? Dynamic pricing?
Will the SOTA model labs even sell API keys to anyone other than partners/whales? Why even that? They are the personalized app devs and hosts!
Man, this is the golden age of building. Not everyone can do it yet, and every project you can imagine is greatly subsidized. How long will that last?
Comment by tern 11 hours ago
- Models will get cheaper, maybe way cheaper
- Model harnesses will get more complex, maybe way more complex
- Local models may become competitive
- Capital-backed access to more tokens may become absurdly advantaged, or not
The only thing I think you can count on is that more money buys more tokens, so the more money you have, the more power you will have ... as always.
But whether some version of the current subsidy, which levels the playing field, will persist seems really hard to model.
All I can say is, the bad scenarios I can imagine are pretty bad indeed—much worse than that it's now cheaper for me to own a car, while it wasn't 10 years ago.
Comment by depr 6 hours ago
Comment by FuckButtons 9 hours ago
Comment by consumer451 8 hours ago
I have never seen a use case where a "lower" model was useful, for me, and especially my users.
I am about to get almost the exact MacBook that you have, but I still don't want to inflict non-SOTA models on my code, or my users.
This is not a judgement against you, or the downloadable weights, I just don't know when it would be appropriate to use those models.
BTW, I very much wish that I could run Opus 4.5 locally. The best that I can do for my users is the Azure agreement that they will not train on their data. I also have that setting set on my claude.ai sub, but I trust them far less.
Disclaimer: No model is even close to Opus 4.5 for agentic tasks. In my own apps, I process a lot of text/complex context and I use Azure GPT 4.1 for limited llm tasks... but for my "chat with the data" UX, Opus 4.5 all day long. It has tested so superior.
Comment by barrenko 8 hours ago
Comment by consumer451 7 hours ago
The one thing I wish for is that Azure Opus 4.5 had json structured output. Last I checked that was in "beta" and only allowed via direct Anthropic API. However, after many thousands of Opus 4.5 Azure API calls with the correct system and user prompts, not even one API call has returned invalid json.
Comment by EnPissant 6 hours ago
I'm also sure your prefill is slow enough to make the model mostly unusable, even at smallish context windows, but entirely at mid to large context.
Comment by andai 11 hours ago
Comment by consumer451 11 hours ago
In my Uber comparison, it was physical hardware on location... taxis, but this is not the case with token delivery.
This is such a complex situation in that regard, however, once the market settles and monopolies are created, eventually the price will be what market can bear. Will that actually create an increase in gross planet product, or will the SOTA token providers just eat up the existing gross planet product, with no increase?
I suppose whoever has the cheapest electricity will win this race to the bottom? But... will that ever increase global product?
___
Upon reflection, the comment above was likely influenced by this truly amazing quote from Satya Nadella's interview on the Dwarkesh podcast. This might be one of the most enlightened things that I have ever heard in regard to modern times:
> Us self-claiming some AGI milestone, that's just nonsensical benchmark hacking to me. The real benchmark is: the world growing at 10%.
https://www.dwarkesh.com/p/satya-nadella#:~:text=Us%20self%2...
Comment by YetAnotherNick 4 hours ago
[1]: https://developer-blogs.nvidia.com/wp-content/uploads/2026/0...
{kind=link}
Comment by fragmede 15 hours ago
Comment by rmunn 13 hours ago
THIS. I get so annoyed when there's a longstanding bug that I know how to fix, the fix would be easy for me, but I'm not given the access I need in order to fix it.
For example, I use Docker Desktop on Linux rather than native Docker, because other team members (on Windows) use it, and there were some quirks in how it handled file permissions that differed from Linux-native Docker; after one too many times trying to sort out the issues, my team lead said, "Just use Docker Desktop so you have the same setup as everyone else, I don't want to spend more time on permissions issues that only affect one dev on the team". So I switched.
But there's a bug in Docker Desktop that was bugging me for the longest time. If you quit Docker Desktop, all your terminals would go away. I eventually figured out that this only happened to gnome-terminal, because Docker Desktop was trying to kill the instance of gnome-terminal that it kicked off for its internal terminal functionality, and getting the logic wrong. Once I switched to Ghostty, I stopped having the issue. But the bug has persisted for over three years (https://github.com/docker/desktop-linux/issues/109 was reported on Dec 27, 2022) without ever being resolved, because 1) it's just not a huge priority for the Docker Desktop team (who aren't experiencing it), and 2) the people for whom it IS a huge priority (because it's bothering them a lot) aren't allowed to fix it.
Though what's worse is a project that is open-source, has open PRs fixing a bug, and lets those PRs go unaddressed, eventually posting a notice in their repo that they're no longer accepting PRs because their team is focusing on other things right now. (Cough, cough, githubactions...)
Comment by pxc 12 hours ago
This exact frustration (in his case, with a printer driver) is responsible for provoking RMS to kick off the free software movement.
Comment by arthurcolle 12 hours ago
Especially if they want to get into enterprise VPCs and "build and manage organizational intelligence"
Comment by storystarling 2 hours ago
Comment by lomase 15 hours ago
Comment by stavros 15 hours ago
Comment by bad_haircut72 15 hours ago
Comment by adastra22 15 hours ago
Comment by stavros 14 hours ago
Comment by adastra22 14 hours ago
(1) a circular chain of duplicate reports, all closed: or
(2) a game of telephone where each issue is subtly different from the next, eventually reaching an issue that has nothing at all to do with yours.
At no point along the way will you encounter an actual human from Anthropic.
Comment by kylequest 15 hours ago
I'll post the whole thing in a Github repo too at some point, but it's taking a while to prettify the code, so it looks more natural :-)
Comment by lifthrasiir 14 hours ago
Comment by embedding-shape 3 hours ago
What specific parts of the ToS does "sharing different code snippets" violate? Not that I don't believe you, just curious about the specifics as it seems like you've already dug through it.
Comment by arianvanp 7 hours ago
Comment by kylequest 13 hours ago
Comment by majkinetor 9 hours ago
Comment by pxc 12 hours ago
Codeberg at least has some integrity around such things.
Comment by huevosabio 6 hours ago
Comment by causalmodels 17 hours ago
Comment by mi_lk 17 hours ago
Comment by n2d4 16 hours ago
Comment by fragmede 15 hours ago
Sometimes prompt engineering is too ridiculous a term for me to believe there's anything to it, other times it does seem there is something to knowing how to ask the AI juuuust the right questions.
Comment by lsaferite 3 hours ago
Comment by adastra22 15 hours ago
Comment by Der_Einzige 15 hours ago
Unironically, the ToS of most of these AI companies should be, and hopefully is legally unenforceable.
Comment by adastra22 14 hours ago
If you want to make this your cause and incur the legal fees and lost productivity, be my guest.
Comment by mlrtime 5 hours ago
Comment by adastra22 2 hours ago
Comment by fragmede 14 hours ago
Comment by frumplestlatz 17 hours ago
Comment by andy12_ 7 hours ago
Very probably. Apparently, it's literally implemented with a React->Text pipeline and it was so badly implemented that they were having problems with the garbage collector executing too frequently.
Comment by stavros 15 hours ago
Comment by skerit 8 hours ago
Comment by rashidae 15 hours ago
Comment by frumplestlatz 11 hours ago
Comment by kordlessagain 14 hours ago
Comment by athrowaway3z 6 hours ago
As for your 200$/mo sub. Dont buy it. If you read the fine print, their 20x usage is _per 5h session_, not overall usage.
Take 2x 100$ if you're hitting the limit.
Comment by boguscoder 14 hours ago
Comment by psychoslave 4 hours ago
Comment by appplication 17 hours ago
Comment by jstummbillig 9 hours ago
That is not the obvious reason for the change. Training models got a lot more expensive than anyone thought it would.
You can of course always cast shade on people's true motivations and intentions, but there is a plain truth here that is simply silly to ignore.
Training "frontier" open LLMs seems to be exactly possible when a) you are Meta, have substantial revenue from other sources and simply are okay with burning your cash reserves to try to make something happen and b) you copy and distill from the existing models.
Comment by seizethecheese 15 hours ago
Comment by cap11235 14 hours ago
Comment by edmundsauto 12 hours ago
Fortunately, many other people can deal with nuance.
Comment by westoncb 18 hours ago
> Since then, the Responses API has evolved to support a special /responses/compact endpoint (opens in a new window) that performs compaction more efficiently. It returns a list of items (opens in a new window) that can be used in place of the previous input to continue the conversation while freeing up the context window. This list includes a special type=compaction item with an opaque encrypted_content item that preserves the model’s latent understanding of the original conversation. Now, Codex automatically uses this endpoint to compact the conversation when the auto_compact_limit (opens in a new window) is exceeded.
Comment by icelancer 17 hours ago
Comment by nubg 13 hours ago
Comment by FuckButtons 9 hours ago
Comment by e1g 7 hours ago
> the Responses API has evolved to support a special /responses/compact endpoint [...] it returns an opaque encrypted_content item that preserves the model’s latent understanding of the original conversation
Comment by xg15 6 hours ago
Comment by e1g 6 hours ago
Comment by whatreason 1 hour ago
There is also another reason, to prevent some attacks related to injecting things in reasoning blocks. Anthropic has published some studies on this. By using encrypted content, openai and rely on it not being modified. Openai and anthropic have started to validate that you're not removing these messages between requests in certain modes like extended thinking for safety and performance reasons
Comment by xg15 6 hours ago
Comment by EnPissant 6 hours ago
Comment by e1g 5 hours ago
Comment by EnPissant 11 hours ago
Comment by kordlessagain 14 hours ago
Comment by swalsh 16 hours ago
Comment by jumploops 20 hours ago
This helps preserve context over many turns, but it can also mean some context is lost between two related user turns.
A strategy that's helped me here, is having the model write progress updates (along with general plans/specs/debug/etc.) to markdown files, acting as a sort of "snapshot" that works across many context windows.
Comment by CjHuber 19 hours ago
I've only used codex with the responses v1 API and there it's the complete opposite. Already generated reasoning tokens even persist when you send another message (without rolling back) after cancelling turns before they have finished the thought process
Also with responses v1 xhigh mode eats through the context window multiples faster than the other modes, which does check out with this.
Comment by jswny 4 hours ago
Comment by xg15 6 hours ago
If the reasoning tokens where persisted, I imagine it would be possible to build up more and more context that's invisible to the user and in the worst case, the model's and the user's "understanding" of the chat might diverge.
E.g. image a chat where the user just wants to make some small changes. The model asks whether it should also add test cases. The user declines and tells the model to not ask about it again.
The user asks for some more changes - however, invisibly to the user, the model keeps "thinking" about test cases, but never telling outside of reasoning blocks.
So suddenly, from the model's perspective, a lot of the context is about test cases, while from the user's POV, it was only one irrelevant question at the beginning.
Comment by olliepro 18 hours ago
Comment by hedgehog 17 hours ago
Comment by hhmc 16 hours ago
Comment by hedgehog 15 hours ago
Comment by ndriscoll 3 hours ago
## Task Management
- Use the projects directory for tracking state
- For code review tasks, do not create a new project
- Within the `open` subdirectory, make a new folder for your project
- Record the status of your work and any remaining work items in a `STATUS.md` file
- Record any important information to remember in `NOTES.md`
- Include links to MRs in NOTES.md.
- Make a `worktrees` subdirectory within your project. When modifying a repo, use a `git worktree` within your project's folder. Skip worktrees for read-only tasks
- Once a project is completed, you may delete all worktrees along with the worktrees subdirectory, and move the project folder to `completed` under a quarter-based time hierarchy, e.g. `completed/YYYY-Qn/project-name`.
I'm dumb with this stuff, but what I've done is set up a folder structure:
dev/
dev/repoA
dev/repoB
...
dev/ai-workflows/
dev/ai-workflows/projects
Comment by fragmede 14 hours ago
Comment by energy123 9 hours ago
Or do you require the tasks be sufficiently unrelated?
Comment by tomashubelbauer 4 hours ago
Comment by ljm 18 hours ago
It’s not the responsibility of the agent to write this transcript, it’s emacs, so I don’t have to worry about the agent forgetting to log something. It’s just writing the buffer to disk.
Comment by vmg12 19 hours ago
Comment by behnamoh 19 hours ago
Comment by pcwelder 12 hours ago
Comment by crorella 20 hours ago
Comment by EnPissant 19 hours ago
I'm pretty sure that Codex uses reasoning.encrypted_content=true and store=false with the responses API.
reasoning.encrypted_content=true - The server will return all the reasoning tokens in an encrypted blob you can pass along in the next call. Only OpenaAI can decrypt them.
store=false - The server will not persist anything about the conversation on the server. Any subsequent calls must provide all context.
Combined the two above options turns the responses API into a stateless one. Without these options it will still persist reasoning tokens in a agentic loop, but it will be done statefully without the client passing the reasoning along each time.
Comment by jumploops 17 hours ago
I would see my context window jump in size, after each user turn (i.e. from 70 to 85% remaining).
Built a tool to analyze the requests, and sure enough the reasoning tokens were removed from past responses (but only between user turns). Here are the two relevant PRs [0][1].
When trying to get to the bottom of it, someone from OAI reached out and said this was expected and a limitation of the Responses API (interesting sidenote: Codex uses the Responses API, but passes the full context with every request).
This is the relevant part of the docs[2]:
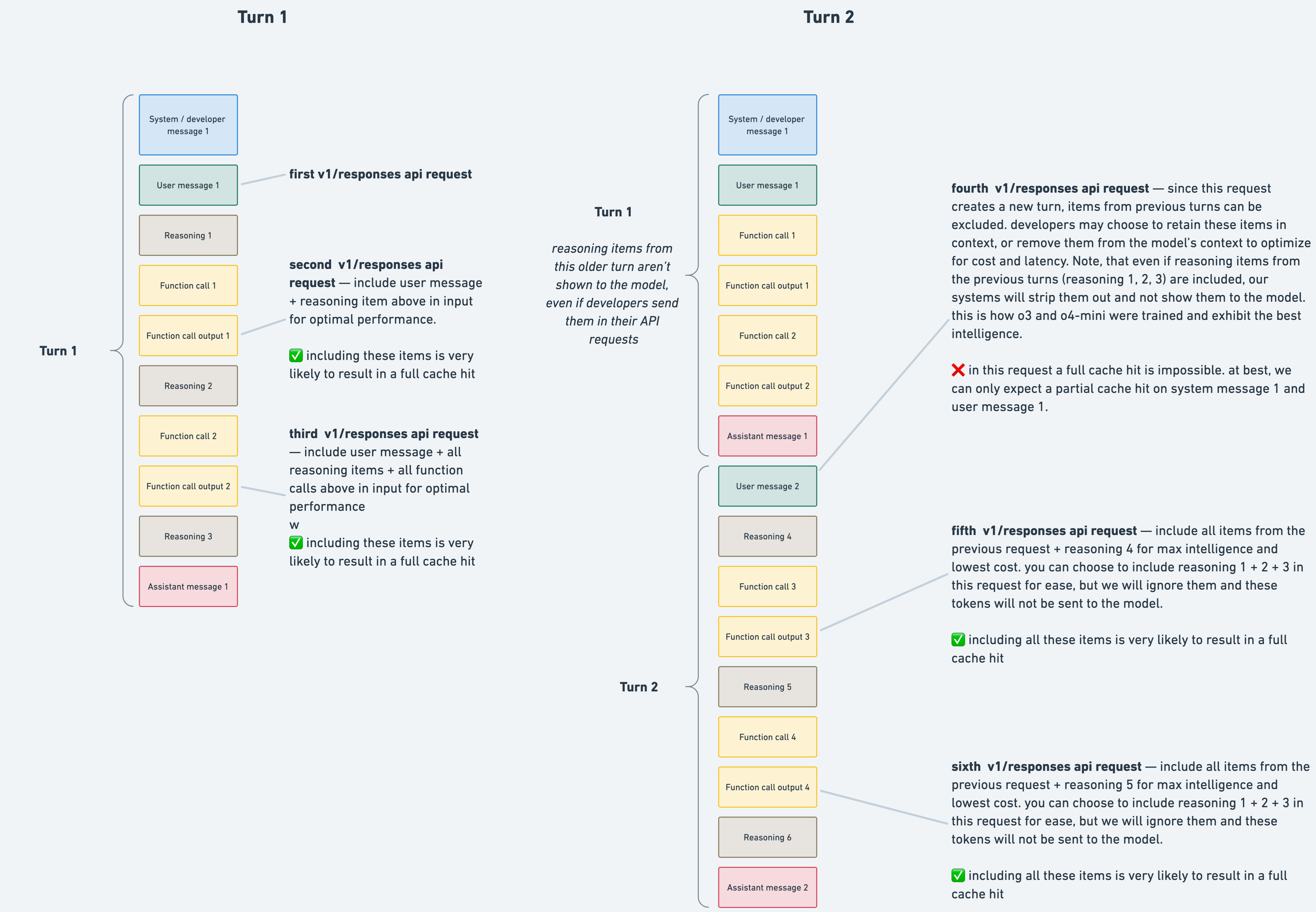
> In turn 2, any reasoning items from turn 1 are ignored and removed, since the model does not reuse reasoning items from previous turns.
[0]https://github.com/openai/codex/pull/5857
[1]https://github.com/openai/codex/pull/5986
[2]https://cookbook.openai.com/examples/responses_api/reasoning...
Comment by EnPissant 17 hours ago
I wonder why the second PR you linked was made then. Maybe the documentation is outdated? Or maybe it's just to let the server be in complete control of what gets dropped and when, like it is when you are using responses statefully? This can be because it has changed or they may want to change it in the future. Also, codex uses a different endpoint than the API, so maybe there are some other differences?
Also, this would mean that the tail of the KV cache that contains each new turn must be thrown away when the next turn starts. But I guess that's not a very big deal, as it only happens once for each turn.
EDIT:
This contradicts the caching documentation: https://developers.openai.com/blog/responses-api/
Specifically:
> And here’s where reasoning models really shine: Responses preserves the model’s reasoning state across those turns. In Chat Completions, reasoning is dropped between calls, like the detective forgetting the clues every time they leave the room. Responses keeps the notebook open; step‑by‑step thought processes actually survive into the next turn. That shows up in benchmarks (TAUBench +5%) and in more efficient cache utilization and latency.
Comment by jumploops 16 hours ago
In either case, the lack of clarity on the Responses API inner-workings isn't great. As a developer, I send all the encrypted reasoning items with the Responses API, and expect them to still matter, not get silently discarded[0]:
> you can choose to include reasoning 1 + 2 + 3 in this request for ease, but we will ignore them and these tokens will not be sent to the model.
[0]https://raw.githubusercontent.com/openai/openai-cookbook/mai...
{kind=link}
Comment by EnPissant 16 hours ago
Yeah, I think you may be correct.
Comment by sdwr 19 hours ago
Comment by behnamoh 19 hours ago
Comment by postalcoder 18 hours ago
Comment by behnamoh 18 hours ago
Comment by postalcoder 18 hours ago
That said, faster inference can't come soon enough.
Comment by behnamoh 18 hours ago
why is that? technical limits? I know cerebras struggles with compute and they stopped their coding plan (sold out!). their arch also hasn't been used with large models like gpt-5.2. the largest they support (if not quantized) is glm 4.7 which is <500B params.
Comment by dayone1 15 hours ago
Comment by lighthouse1212 1 hour ago
Comment by coffeeaddict1 19 hours ago
Comment by adam_patarino 2 hours ago
Comment by coffeeaddict1 1 hour ago
Comment by adam_patarino 45 minutes ago
Comment by toephu2 17 hours ago
Comment by wahnfrieden 19 hours ago
Comment by SafeDusk 16 hours ago
I use headless codex exec a lot, but struggles with its built-in telemetry support, which is insufficient for debugging and optimization.
Thus I made codex-plus (https://github.com/aperoc/codex-plus) for myself which provides a CLI entry point that mirrors the codex exec interface but is implemented on top of the TypeScript SDK (@openai/codex-sdk).
It exports the full session log to a remote OpenTelemetry collector after each run which can then be debugged and optimized through codex-plus-log-viewer.
Comment by fcoury 22 minutes ago
Comment by daxfohl 16 hours ago
Comment by energy123 12 hours ago
Comment by mkw5053 20 hours ago
Comment by ipotapov 4 hours ago
Comment by written-beyond 19 hours ago
However, I decided to try codex cli after hearing they rebuilt it from the ground up and used rust(instead of JS, not implying Rust==better). It's performance is quite literally insane, its UX is completely seamless. They even added small nice to haves like ctrl+left/right to skip your cursor to word boundaries.
If you haven't I genuinely think you should give it a try you'll be very surprised. Saw Theo(yc ping labs) talk about how open ai shouldn't have wasted their time optimizing the cli and made a better model or something. I highly disagree after using it.
Comment by georgeven 19 hours ago
I work on SSL bio acoustic models as context.
Comment by behnamoh 19 hours ago
Comment by straydusk 8 hours ago
I'm struggling with landing in a good way to use them together. If you have a way you like, I'd love to hear it.
Comment by copperx 19 hours ago
Comment by behnamoh 18 hours ago
Comment by copperx 11 hours ago
CC doesn't support it natively, so I'm assuming is some sort of mod, and it still outclasses Opus? That's interesting.
Do you mind sharing what tool/mod you are using?
Comment by wahnfrieden 19 hours ago
Comment by behnamoh 18 hours ago
Comment by copperx 11 hours ago
Comment by wahnfrieden 10 hours ago
Comment by jswny 4 hours ago
Comment by wahnfrieden 2 hours ago
Comment by copperx 10 hours ago
Comment by wahnfrieden 15 hours ago
Comment by ewoodrich 19 hours ago
But tbh OpenAI openly supporting OpenCode is the bigger draw for me on the plan but do want to spend more time with native Codex as a base of comparison against OpenCode when using the same model.
I’m just happy to have so many competitive options, for now at least.
Comment by behnamoh 19 hours ago
- hooks (this is a big one)
- better UI to show me what changes are going to be made.
the second one makes a huge diff and it's the main reason I stopped using opencode (lots of other reasons too). in CC, I am shown a nice diff that I can approve/reject. in codex, the AI makes lots of changes but doesn't pin point what changes it's doing or going to make.
Comment by written-beyond 19 hours ago
Comment by nl 14 hours ago
But it's much much worse at writing issues than Claude models.
Comment by zoho_seni 17 hours ago
How you using hooks?
Comment by rco8786 14 minutes ago
My main hooks are desktop notifications when Claude requires input or finishes a task. So I can go do other things while it churns and know immediately when it needs me.
Comment by estimator7292 18 hours ago
However, it seems to really only be good at coding tasks. Anything even slightly out of the ordinary, like planning dialogue and plot lines it almost immediately starts producing garbage.
I did get it stuck in a loop the other day. I half-assed a git rebase and asked codex to fix it. It did eventually resolve all debased commits, but it just kept going. I don't really know what it was doing, I think it made up some directive after the rebase completed and it just kept chugging until I pulled the plug.
The only other tool I've tried is Aider, which I have found to be nearly worthless garbage
Comment by williamstein 19 hours ago
I also was annoyed by Theo saying that.
Comment by CuriouslyC 19 hours ago
I have a tool that reduces agent token consumption by 30%, and it's only viable because I can hook the harness and catch agents being stupid, then prompt them to be smarter on the fly. More at https://sibylline.dev/articles/2026-01-22-scribe-swebench-be...
Comment by procinct 19 hours ago
Comment by AlexCoventry 14 hours ago
Comment by behnamoh 19 hours ago
Comment by estimator7292 18 hours ago
Comment by behnamoh 18 hours ago
Comment by songodongo 5 hours ago
Comment by karmasimida 12 hours ago
This is the biggest UX killer,unfortunately
Comment by tecoholic 19 hours ago
Comment by sumedh 19 hours ago
Generally I have noticed Gpt 5.2 codex is slower compared to Sonnet 4.5 in Claude Code.
Comment by nl 14 hours ago
In smart mode it explores with Gemini Flash and writes with Opus.
Opus is roughly the same speed as Codex, depending on thinking settings.
Comment by nl 14 hours ago
Comment by anukin 16 hours ago
Comment by tecoholic 4 hours ago
Comment by gzalo 11 hours ago
Why wouldnt they just expose the files directly? Having the model ask for them as regular files sounds a bit odd
Comment by mike_hearn 3 hours ago
Comment by rvnx 19 hours ago
Call the model. If it asks for a tool, run the tool and call again (with the new result appended). Otherwise, done
{kind=link}
Comment by jmkni 19 hours ago
Comment by rvnx 19 hours ago
https://github.com/anthropics/claude-plugins-official/commit...
Comment by jmkni 19 hours ago
Comment by albert_e 13 hours ago
The "Listen to article" media player at the top of the post -- was super quick to load on mobile but took two attempts and a page refresh to load on desktop.
If I want to listen as well as read the article ... the media player scrolls out of view along with the article title as we scroll down ..leaving us with no way to control (pause/play) the audio if needed.
There are no playback controls other than pause and speed selector. So we cannot seek or skip forward/backward if we miss a sentence. the time display on the media player is also minimal. Wish these were a more accessible standardized feature set available on demand and not limited by what the web designer of each site decides.
I asked "Claude on Chrome" extension to fix the media player to the top. It took 2 attempts to get it right. (It was using Haiku by default -- may be a larger model was needed for this task). I think there is scope to create a standard library for such client side tweaks to web pages -- sort of like greasemonkey user scripts but at a slightly higher level of abstraction with natural language prompts.
Comment by doanbactam 12 hours ago
Comment by kordlessagain 14 hours ago
Comment by dfajgljsldkjag 20 hours ago
Comment by mohsen1 18 hours ago
Or am I not understanding this right?
Comment by I_am_tiberius 17 hours ago
Comment by evilduck 17 hours ago
I have this set up as a shell script (or you could make it an alias):
codex --config model="gpt-oss-120b" --config model_provider=custom
[model_providers.custom]
name = "Llama-swap Local Service"
base_url = "http://localhost:8080/v1"
http_headers = { "Authorization" = "Bearer sk-123456789" }
wire_api = "chat"
# Default model configuration
model = "gpt-oss-120b"
model_provider = "custom"
Comment by ltbarcly3 13 hours ago
Claude Code is very effective. Opus is a solid model and claude very reliably solves problems and is generally efficient and doesn't get stuck in weird loops or go off in insane tangents too often. You can be very very efficient with claude code.
Gemini-cli is quite good. If you set `--model gemini-3-pro-preview` it is quite usable, but the flash model is absolute trash. Overall gemini-3-pro-preview is 'smarter' than opus, but the tooling here is not as good as claude code so it tends to get stuck in loops, or think for 5 minutes, or do weird extreme stuff. When Gemini is on point it is very very good, but it is inconsistent and likely to mess up so much that it's not as productive to use as claude.
Codex is trash. It is slow, tends to fail to solve problems, gets stuck in weird places, and sometimes has to puzzle on something simple for 15 minutes. The codex models are poor, and forcing the 5.2 model is expensive, and even then the tooling is incredibly bad and tends to just fail a lot. I check in to see if codex is any good from time to time and every time it is laughably bad compared to the other two.
Comment by cactusplant7374 3 hours ago
Comment by MultifokalHirn 20 hours ago
Comment by ppeetteerr 19 hours ago
Comment by sdwvit 19 hours ago
Comment by ppeetteerr 19 hours ago
Comment by rvnx 19 hours ago
Codex works by repeatedly sending a growing prompt to the model, executing any tool calls it requests, appending the results, and repeating until the model returns a text response