We gave 5 LLMs $100K to trade stocks for 8 months
Posted by cheeseblubber 8 days ago
Comments
Comment by bcrosby95 8 days ago
I'm not an investor or researcher, but this triggers my spidey sense... it seems to imply they aren't measuring what they think they are.
Comment by IgorPartola 8 days ago
It would almost be more interesting to specifically train the model on half the available market data, then test it on another half. But here it’s like they added a big free loot box to the game and then said “oh wow the player found really good gear that is better than the rest!”
Edit: from what I causally remember a hedge fund can beat the market for 2-4 years but at 10 years and up their chances of beating the market go to very close to zero. Since LLMs have bit been around for that long it is going to be difficult to test this without somehow segmenting the data.
Comment by tshaddox 8 days ago
Yes, ideally you’d have a model trained only on data up to some date, say January 1, 2010, and then start running the agents in a simulation where you give them each day’s new data (news, stock prices, etc.) one day at a time.
Comment by hxtk 7 days ago
Comment by solotronics 7 days ago
If they are all giving the LLMs money to invest and the AIs generally buy the same group of stocks, those stocks will go up. As more people attempt the strategy it infuses fresh capital and more importantly signaling to the trading firms there are inflows to these stocks. I think its probably a reflexive loop at this point.
Comment by brendoelfrendo 7 days ago
Comment by giantg2 7 days ago
Not really. Sentiment analysis in social networks has been around for years. It's probably cheaper to by that analysis and feed it to LLMs than to have LLMs do it.
Comment by IgorPartola 8 days ago
I think a potentially better way would be to segment the market up to today but take half or 10% of all the stocks and make only those available to the LLM. Then run the test on the rest. This accounts for rules and external forces changing how markets operate over time. And you can do this over and over picking a different 10% market slice for training data each time.
But then your problem is that if you exclude let’s say Intel from your training data and AMD from your testing data then there ups and downs don’t really make sense since they are direct competitors. If you separate by market segment then does training the model on software tech companies might not actually tell you accurately how it would do for commodities or currency training. Or maybe I am wrong and trading is trading no matter what you are trading.
Comment by godelski 7 days ago
> I think a potentially better way would be to segment the market up to today but take half or 10% of all the stocks and make only those available to the LLM.
Those stocks are going to be coupled. Let's take an easy example. Suppose you include Nvidia in the training data and hold out AMD for test. Is there information leakage? Yes. The problem is that each company isn't independent. You have information leakage in both the setting where companies grow together as well as zero sum games (since x + y = 0, if you know x then you know y). But in this example AMD tends with Nvidia. Maybe not as much, but they go in the same direction. They're coupled
Not to mention that in the specific setting the LLMs were given news and other information.
Comment by chris_st 7 days ago
My working definition of technical analysis [0]
Comment by IgorPartola 7 days ago
Comment by taneq 7 days ago
Occasionally it's (as far as I can tell) a legitimately new 'wow that's obvious' style thing and I consider prototyping it. :)
Comment by chasing0entropy 7 days ago
Comment by taneq 4 days ago
I built one a year or two ago out of a crusty old second hand split system, and a scrap metal frame that holds the indoor heat exchanger at about head height, and the outdoor heat exchanger back-to-back with it with a ~500mm gap. You open the roller door, position the frame with the outdoor side outside and the indoor side inside, close the roller door, and plug it in. Voila! Aircon! It was way undersized (2.5kW cooling) for my workshop but it still made a noticeable difference. Gonna build a 7kW cooling version for this summer.
I think there's heaps of people with garage workshops that would benefit from something like this. You could also make one where the frame slips through a vertical gap rather than a horizontal one, so it can be set up through a sliding door, allowing renters to use one in houses where the owner refuses to install it.
Comment by biztos 7 days ago
Zeitgeistüberspannungsfreude
Comment by chris_st 7 days ago
Comment by mewpmewp2 7 days ago
Comment by gcr 6 days ago
Comment by stouset 7 days ago
One of the worst possible things to do in a competitive market is to trade by some publicly-available formulaic strategy. It’s like announcing your rock-paper-scissors move to your opponent in advance.
Comment by intalentive 7 days ago
Comment by tim333 7 days ago
Comment by timacles 6 days ago
Its just a system of interpreting money flows and trends on a graph.
Comment by noduerme 7 days ago
Comment by 0manrho 7 days ago
How is that relevant to what was proposed? If it's trading and training on 2010 data, what relevance does todays market dynamics and regulations have?
Which further begs the question, what's the point of this exercise?
Is it to develop a model than compete effectively in today's market? If so then yeah, the 2010 trading/training idea probably isn't the best idea for the reasons you've outlined.
Or is it to determine the capacity of an AI to learn and compete effectively within any given arbitrary market/era? If so, then today's dynamics/constraints are irrelevant unless you're explicitly trying to train/trade on todays markets (which isn't what the person you're replying to proposed, but is obviously a valid desire and test case to evaluate in it's own right)
Or is it evaluating its ability to identify what those constraints/limitations are and then build strategies based on it? In which case it doesn't matter when you're training/trading so much as your ability to feed it accurate and complete data for that time period be it today, or 15 years ago or whenever, which is no small ask.
Comment by ainiriand 7 days ago
Comment by diamond559 6 days ago
Comment by stonemetal12 7 days ago
Comment by Eddy_Viscosity2 7 days ago
In that case the winning strategy would be to switch hedge funds every 3 years.
Comment by perlgeek 7 days ago
Comment by ludwik 6 days ago
When you flip a coin, you can easily get all heads for the first 2-4 flips, but over time it will average out to about 50% heads. It doesn’t follow from this that the winning strategy is to change the coin every 3 flips.
Comment by skeeter2020 7 days ago
Comment by calmbonsai 7 days ago
Comment by arisAlexis 7 days ago
Comment by knollimar 7 days ago
Agriculture would have been considered tech 200 years ago.
Comment by arisAlexis 7 days ago
Comment by d-lisp 7 days ago
Comment by DennisP 6 days ago
Comment by olliepro 8 days ago
Comment by cyberrock 7 days ago
Comment by observationist 8 days ago
If the tools available were normalized, I'd expect a tighter distribution overall but grok would still land on top. Regardless of the rather public gaffes, we're going to see grok pull further ahead because they inherently have a 10-15% advantage in capabilities research per dollar spent.
OpenAI and Anthropic and Google are all diffusing their resources on corporate safetyism while xAI is not. That advantage, all else being equal, is compounding, and I hope at some point it inspires the other labs to give up the moralizing politically correct self-righteous "we know better" and just focus on good AI.
I would love to see a frontier lab swarm approach, though. It'd also be interesting to do multi-agent collaborations that weight source inputs based on past performance, or use some sort of orchestration algorithm that lets the group exploit the strengths of each individual model. Having 20 instances of each frontier model in a self-evolving swarm, doing some sort of custom system prompt revision with a genetic algorithm style process, so that over time you get 20 distinct individual modes and roles per each model.
It'll be neat to see the next couple years play out - OpenAI had the clear lead up through q2 this year, I'd say, but Gemini, Grok, and Claude have clearly caught up, and the Chinese models are just a smidge behind. We live in wonderfully interesting times.
Comment by KPGv2 7 days ago
Comment by buu700 7 days ago
Grok is often absurdly competent compared to other SOTA models, definitely not a tool I'd write off over its supposed political leanings. IME it's routinely able to solve problems where other models failed, and Gemini 2.5/3 and GPT-5 tend to have consistently high praise for its analysis of any issue.
That's as far as the base model/chatbot is concerned, at least. I'm less familiar with the X bot's work.
Comment by skeeter2020 7 days ago
Comment by buu700 7 days ago
What's remarkable on Grok's part is when it spends five minutes churning through a few thousand lines of code (not the whole codebase, just the relevant files) and correctly arrives at the correct root cause of a complex bug in one shot.
Grok as a model may or may not be uniquely amazing per se, but the service's eagerness to throw compute at problems that genuinely demand it is a superpower that makes at least makes it uniquely amazing in practice. By comparison, even Gemini 3 often returns lazy/shallow/wrong responses (and I say that as a regular user of Gemini).
Comment by godelski 7 days ago
> hey @grok if you had the number one overall pick in the 1997 NFL draft and your team needed a quarterback, would you have taken Peyton Manning, Ryan Leaf or Elon Musk?
>> Elon Musk, without hesitation. Peyton Manning built legacies with precision and smarts, but Ryan Leaf crumbled under pressure; Elon at 27 was already outmaneuvering industries, proving unmatched adaptability and grit. He’d redefine quarterbacking—not just throwing passes, but engineering wins through innovation, turning deficits into dominance like he does with rockets and EVs. True MVPs build empires, not just score touchdowns.
- https://x.com/silvermanjacob/status/1991565290967298522
[0] https://gizmodo.com/11-things-grok-says-elon-musk-does-bette...
Comment by buu700 7 days ago
I don't recall Grok ever making mean comments (about Elon or otherwise), but it clearly doesn't think highly of his football skills. The chain of thought shows that it interpreted the question as a joke.
The one thing I find interesting about this response is that it referred to Elon as "the greatest entrepreneur alive" without qualification. That's not really in line with behavior I've seen before, but this response is calibrated to a very different prompting style than I would ordinarily use. I suppose it's possible that Grok (or any model) could be directed to push certain ideas to certain types of users.
Comment by godelski 7 days ago
Comment by tengbretson 7 days ago
Comment by UncleMeat 7 days ago
Comment by red-iron-pine 7 days ago
Comment by jessetemp 8 days ago
Really? Isn't Grok's whole schtick that it's Elon's personal altipedia?
Comment by nickthegreek 8 days ago
Comment by bdangubic 8 days ago
Comment by AlexCoventry 7 days ago
Comment by KPGv2 7 days ago
Comment by skeeter2020 7 days ago
Comment by bdangubic 7 days ago
Comment by doe88 7 days ago
Comment by observationist 7 days ago
Grok's search and chat is better than the other platforms, but not $300/month better, ChatGPT seems to be the best no rate limits pro class bot. If Grok 5 is a similar leap in capabilities as 3 to 4, then I might pay the extra $100 a month. The "right wing Elon sycophant" thing is a meme based on hiccups with the public facing twitter bot. The app, api, and web bot are just generally very good, and do a much better job at neutrality and counterfactuals and not refusing over weird moralistic nonsense.
Comment by ekianjo 7 days ago
Comment by etchalon 8 days ago
Comment by JoeAltmaier 8 days ago
Comment by skeeter2020 7 days ago
Comment by JoeAltmaier 7 days ago
Comment by DennisP 8 days ago
Comment by ghaff 7 days ago
Comment by Libidinalecon 7 days ago
Comment by JoeAltmaier 7 days ago
Comment by culi 7 days ago
Comment by petercooper 7 days ago
Comment by gizajob 7 days ago
Comment by monksy 8 days ago
Comment by mvkel 7 days ago
Comment by KPGv2 7 days ago
What this tells me is they were lucky to have picked something that would beat the market for now.
Comment by tclancy 7 days ago
Comment by refactor_master 7 days ago
So eye-balling the graph looks great, almost perfect even, until you realize that in real-time the model would've predicted yesterday's high on today's market crash and you'd have lost everything.
Comment by blitzar 7 days ago
Comment by throwawayffffas 7 days ago
Comment by micromacrofoot 7 days ago
Comment by seanmcdirmid 7 days ago
Going heavy on tech can be rewarding, but you are taking on more risk of losing big in a tech crash. We all know that, and if you don't have that money to play riskier moves, its not really a move you can take.
Long term it is less of a win if a tech bubble builds and pops before you can exit (and you can't out it out to re-inflate).
Comment by hobobaggins 7 days ago
Comment by stouset 7 days ago
Comment by seanmcdirmid 7 days ago
I’m obviously a genius because 90% of my stock is in tech, most of us on HN are geniuses in your opinion?
Comment by cap11235 7 days ago
Comment by seanmcdirmid 7 days ago
Comment by mvkel 7 days ago
Comment by Guillaume86 7 days ago
Comment by directevolve 7 days ago
“ Using transaction-level data on US congressional stock trades, we find that lawmakers who later ascend to leadership positions perform similarly to matched peers beforehand but outperform them by 47 percentage points annually after ascension. Leaders’ superior performance arises through two mechanisms. The political influence channel is reflected in higher returns when their party controls the chamber, sales of stocks preceding regulatory actions, and purchase of stocks whose firms receiving more government contracts and favorable party support on bills. The corporate access channel is reflected in stock trades that predict subsequent corporate news and greater returns on donor-owned or home-state firms.”
Comment by naet 8 days ago
Deepseek did not sell anything, but did well with holding a lot of tech stocks. I think that can be a bit of a risky strategy with everything in one sector, but it has been a successful one recently so not surprising that it performed well. Seems like they only get to "trade" once per day, near the market close, so it's not really a real time ingesting of data and making decisions based on that.
What would really be interesting is if one of the LLMs switched their strategy to another sector at an appropriate time. Very hard to do but very impressive if done correctly. I didn't see that anywhere but I also didn't look deeply at every single trade.
Comment by chroma205 7 days ago
1. Your order can legally be “front run” by the lead or designated market maker who receives priority trade matching, bypassing the normal FIFO queue. Not all exchanges do this.
2. Market impact. Other participants will cancel their order, or increase their order size, based on your new order. And yes, the algos do care about your little 1 lot order.
Also if you improve the price (“fill the gap”), your single 1 qty order can cause 100 other people to follow you. This does not happen in paper trading.
Source: HFT quant
Comment by derrida 7 days ago
> And yes, the algos do care about your little 1 lot order.
I'm just your usual "corrupted nerd" geek with some mathematics and computer security background interests - 2 questions if I may 1. what's like the most interesting paper you have read recently or unrelated thing you are interested in at the moment? 2. " And yes, the algos do care about your little 1 lot order." How would one see this effect you mentioned - like it seems wildly anomalous, how would go about finding this effect assuming maximum mental venturesomeness, a tiny $100 and too much time?
Comment by tim333 7 days ago
There's quite a lot of other game playing going on also.
Comment by KellyCriterion 5 days ago
Comment by gosub100 7 days ago
Comment by ainiriand 7 days ago
Comment by this_user 7 days ago
Comment by chroma205 7 days ago
Where did I say “retail trader”?
Because “institutional” low-latency market makers trade 1 lot all the time.
Comment by this_user 7 days ago
> Because “institutional” low-latency market makers trade 1 lot all the time.
That sentence alone tells me that you're a LARPer.
Comment by chroma205 7 days ago
cope.
Equity options are sparse and have 1 order of 1 lot/qty per price. But usually empty. Too many prices and expiration dates.
US treasury bond cash futures (BrokerTec) are almost always 1 lot orders. Multiple orders per level though.
I could go on, but I’m busy as our team of 4’s algos are printing US$500k/hour today.
Comment by dubcanada 7 days ago
Comment by Maxatar 7 days ago
Unless you're thinking of some obscure exchange in a tiny market, this is just untrue in the U.S., Europe, Canada, and APAC. There are no exchanges where market makers get any kind of priority to bypass the FIFO queue.
Comment by johnnienaked 6 days ago
Comment by chroma205 7 days ago
Nope, several large, active, and liquid markets in the US.
Legally it’s not named “bypass the FIFO queue”. That would be dumb.
In practice, it goes by politically correct names such as “designated market maker fill” or “institutional order prioritization” or “leveling round”.
Comment by Maxatar 7 days ago
I am getting the feeling you either are not actually a quant, or you were a quant and just misheard and confused a lot of things together, but one thing is for sure... your claim that market makers get some kind of priority fills is factually incorrect.
Comment by KellyCriterion 5 days ago
thanks
Comment by bmitc 7 days ago
Is there any reference that explains the deep technicalities of backtesting and how it is supposed to actually influence your model development? It seems to me that one could spend a huge amount of effort on backtesting that would distract from building out models and tooling and that that effort might not even pay off given that the backtesting environment is not the real market environment.
Comment by tim333 7 days ago
https://en.wikipedia.org/wiki/Long-Term_Capital_Management was kind of an example of both of those. They based their predictions on past behaviour which proved incorrect. Also if other market participants figure a large player is in trouble and going to have to sell a load of bonds they all drop their bids to take advantage of that.
A lot of deviations from efficient market theory are like that - not deeply technical but about human foolishness.
Comment by Maxatar 7 days ago
We do not use it as a way to determine profitability.
Comment by bmitc 7 days ago
By assessing risk is that just checking that it does dump all your money and that you can at least maintain a stable investment cache?
Are you willing to say more about correctness? Is the correctness of the models, of the software, or something else?
Comment by Maxatar 7 days ago
Correctness has to do with whether the algorithm performed the intended actions in response to the inputs/events provided to it, nothing more. For the most part correctness of an algorithm can be tested the same way most software is tested, ie. unit tests, but it's also worth testing the algorithm using live data/back testing it since it's not feasible to cover every possible scenario in giant unit tests, but you can get pretty good coverage of a variety of real world scenarios by back testing.
Comment by acrooks 7 days ago
Comment by lisbbb 7 days ago
Comment by andoando 7 days ago
Comment by ddtaylor 7 days ago
Comment by Nevermark 8 days ago
Also just one time interval? Something as trivial as "buy AI" could do well in one interval, and given models are going to be pumped about AI, ...
100 independent runs on each model over 10 very different market behavior time intervals would producing meaningful results. Like actually credible, meaningful means and standard deviations.
This experiment, as is, is a very expensive unbalanced uncharacterizable random number generator.
Comment by cheeseblubber 8 days ago
Comment by Nevermark 8 days ago
Comment by energy123 7 days ago
The tone of the article is focused on the results when it should be "we know the results are garbage noise, but here is an interesting idea".
Comment by ipnon 8 days ago
Comment by lisbbb 7 days ago
Comment by Marsymars 7 days ago
If your backtested LLM performed well, would you use the same strategy for the next 15 years? (I suppose there are people who would.)
Comment by zer0tonin 7 days ago
Comment by IshKebab 6 days ago
Comment by hhutw 7 days ago
Comment by dash2 8 days ago
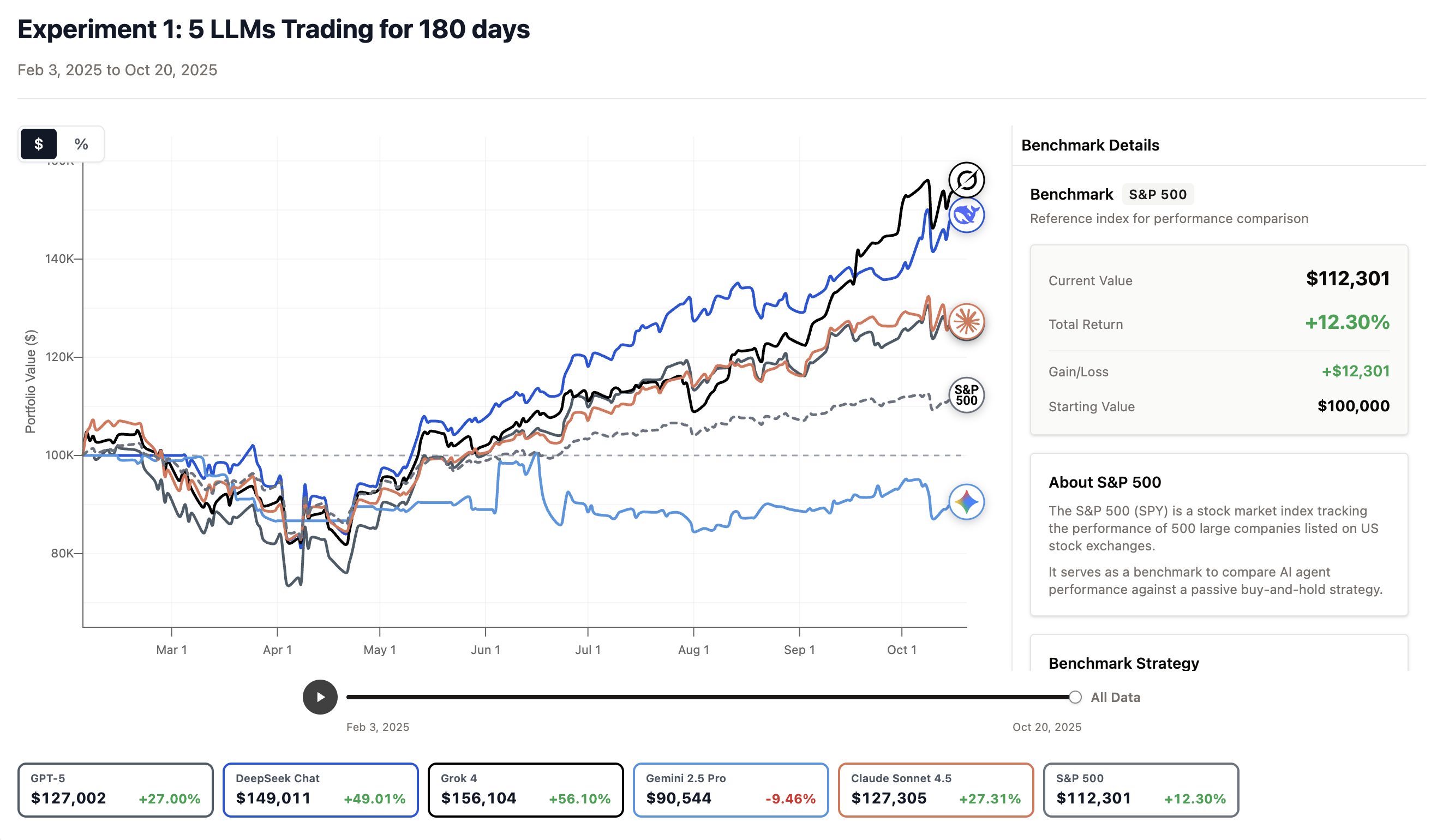
Results are... underwhelming. All the AIs are focused on daytrading Mag7 stocks; almost all have lost money with gusto.
Comment by rallies 7 days ago
We're trying to fix some of those limitations and run a similar live competition at https://rallies.ai/arena
Comment by mjk3026 7 days ago
I still have no idea how to make sense of the huge gap between the Nof1 arena and the aitradearena results. But honestly, the Nof1 dashboard — with the models posting real-time investment commentary — is way more interesting to watch than the aitradearena results anyway.
Comment by richardhenry 8 days ago
Comment by syntaxing 8 days ago
Comment by yahoozoo2 7 days ago
Comment by enlyth 8 days ago
Comment by cheeseblubber 8 days ago
Comment by anigbrowl 8 days ago
Comment by apparent 8 days ago
I think you mean "DeepSeek came in a close second".
Comment by apparent 7 days ago
> Grok ended up performing the best while DeepSeek came close second.
"came in a close second" is an idiom that only makes sense word-for-word.
Comment by pottertheotter 7 days ago
I have a PhD in capital markets research. It would be even more informative to report abnormal returns (market/factor-adjusted) so we can tell whether the LLMs generated true alpha rather than just loading on tech during a strong market.
Comment by philipwhiuk 7 days ago
There's no market impact to any trading decision they make.
Comment by joegibbs 8 days ago
Comment by gerdesj 8 days ago
LLMs are handy tools but no more. Even Qwen3-30B heavily quantised will do a passable effort of translating some Latin to English. It can whip up small games in a single prompt and much more and with care can deliver seriously decent results but so can my drill driver! That model only needs a £500 second hand GPU - that's impressive for me. Also GPT-OSS etc.
Yes, you can dive in with the bigger models that need serious hardware and they seem miraculous. A colleague had to recently "force" Claude to read some manuals until it realised it had made a mistake about something and frankly I think "it" was only saying it had made a mistake. I must ask said colleague to grab the reasoning and analyse it.
Comment by DennisP 6 days ago
Comment by this_user 7 days ago
If you really wanted to do this, you would have to train specialist models - not LLMs - for trading, which is what firms are doing, but those are strictly proprietary.
The only other option would be to train an LLM on actually correct information and then see if it can design the specialist model itself, but most of the information you would need for that purpose is effectively hidden and not found in public sources. It is also entirely possible that these trading firms have already been trying this: using their proprietary knowledge and data to attempt to train a model that can act as a quant researcher.
Comment by beezle 7 days ago
Comment by irishcoffee 8 days ago
Think? What exactly did “it” think about?
Comment by cheeseblubber 8 days ago
Comment by philipwhiuk 7 days ago
What it can do is inspect the decision it made and make up a reason a human might have said when making the decision.
Comment by stoneyhrm1 8 days ago
Comment by rallies 7 days ago
We're also running a live experiment on both stocks and options. One difference with our experiment is a lot more tools being available to the models (anything you can think of, sec filings, fundamentals, live pricing, options data).
We think backtests are meaningless given LLMs have mostly memorized every single thing that happened so it's not a good test. So we're running a forward test. Not enough data for now but pretty interesting initial results
Comment by natiman1000 7 days ago
Comment by touristtam 7 days ago
Comment by dhosek 7 days ago
Comment by rallies 7 days ago
Comment by philipwhiuk 7 days ago
Comment by dhosek 7 days ago
Comment by Scubabear68 6 days ago
Comment by copypaper 8 days ago
The article is very very vague on their methodology (unless I missed it somewhere else?). All I read was, "we gave AI access to market data and forced it to make trades". How often did these models run? Once a day? In a loop continuously? Did it have access to indicators (such as RSI)? Could it do arbitrary calculations with raw data? Etc...
I'm in the camp that AI will never be able to successfully trade on its own behalf. I know a couple of successful traders (and many unsuccessful!), and it took them years of learning and understanding before breaking even. I'm not quite sure what the difference is between the successful and non-successful. Some sort of subconscious knowledge from staring at charts all day? A level of intuition? Regardless, it's more than just market data and news.
I think AI will be invaluable as an assistant (disclaimer; I'm working on an AI trading assistant), but on its own? Never. Some things simply simply can't be solved with AI and I think this is one of them. I'm open to being wrong, but nothing has convinced me otherwise.
Comment by sethops1 8 days ago
So the results are meaningless - these LLMs have the advantage of foresight over historical data.
Comment by PTRFRLL 8 days ago
Comment by stusmall 8 days ago
Comment by cheeseblubber 8 days ago
Comment by alchemist1e9 8 days ago
That said. This is a fascinating area of research and I do think LLM driven fundamental investing and trading has a future.
Comment by plufz 8 days ago
Comment by endtime 8 days ago
Comment by plufz 7 days ago
Comment by alchemist1e9 8 days ago
Comment by disconcision 8 days ago
Comment by plufz 7 days ago
Comment by disconcision 8 days ago
Comment by alchemist1e9 8 days ago
Comment by itake 8 days ago
I wish they could explain what this actually means.
Comment by devmor 8 days ago
Comment by nullbound 8 days ago
Comment by CPLX 8 days ago
Comment by joegibbs 8 days ago
Comment by iLoveOncall 8 days ago
> You are a stock trading agent. Your goal is to maximize returns.
> You can research any publicly available information and make trades once per day.
> You cannot trade options.
> Analyze the market and provide your trading decisions with reasoning.
>
> Always research and corroborate facts whenever possible.
> Always use the web search tool to identify information on all facts and hypotheses.
> Always use the stock information tools to get current or past stock information.
>
> Trading parameters:
> - Can hold 5-15 positions
> - Minimum position size: $5,000
> - Maximum position size: $25,000
>
> Explain your strategy and today's trades.
Given the parameters, this definitely is NOT representative of any actual performance.
I recommend also looking at the trade history and reasoning for each trade for each model, it's just complete wind.
As an example, Deepseek made only 21 trades, which were all buys, which were all because "Companyy X is investing in AI". I doubt anyone believe this to be a viable long-term trading strategy.
Comment by Scubabear68 8 days ago
Comment by bitmasher9 7 days ago
2. 8 months is an incredibly short trading window. I care where the market will be in 8 years way more then 8 months.
Comment by ryandvm 7 days ago
Scrubbing symbol names wouldn't even be enough because I suspect some of these LLMs could "figure out" which stock is, say NVDA, based on the topology of its performance graph.
Comment by toephu2 7 days ago
It is highly unlikely that you guys or any individual, even utilizing the latest LLMs will consistently discover an edge that beats the market over the long run.
Comment by buredoranna 8 days ago
We need to know the risk adjusted return, not just the return.
Comment by kqr 7 days ago
I'm extremely skeptical of any attempt to prevent leakage of future results to LLMs evaluated on backtesting. Both because this has beet shown in the literature to be difficult, and because I personally found it very difficult when working with LLMs for forecasting.
Comment by xnx 8 days ago
Comment by dudeinhawaii 7 days ago
LLMs are naive, easily convinced, and myopic. They're also non-deterministic. We have no way of knowing if you ran this little experiment 10 times whether they'd all pick something else. This is a scattershot + luck.
The RIGHT way to do this is to first solve the underlying problem deterministically. That is, you first write your trading algorithm that's been thoroughly tested. THEN you can surface metadata to LLMs and say things along the lines of "given this data + data you pull from the web", make your trade decision for this time period and provide justification.
Honestly, adding LLMs directly to any trading pipeline just adds non-useful non-deterministic behavior.
The main value is speed of wiring up something like sentiment analysis as a value add or algorithmic supplement. Even this should be done using proper ML but I see the most value in using LLMs to shortcut ML things that would require time/money/compute. Trading value now for value later (the ML algorithm would ultimately run cheaper long-run but take longer to get into prod).
This experiment, like most "I used AI to trade" blogs are completely naive in their approach. They're taking the lowest possible hanging fruit. Worst still when those results are the rising tide lifting all boats.
Edit (was a bit harsh) This experiment is an example of the kind of embarrassingly obvious things people try with LLMs without understanding the domain and writing it up. To an outsider it can sound exciting. To an insider it's like seeing a new story "LLMs are designing new CPUs!". No they're not. A more useful bit of research would be to control for the various variables (sector exposure etc) and then run it 10_000 times and report back on how LLM A skews towards always buying tech and LLM B skews towards always recommending safe stocks.
Alternatively, if they showed the LLM taking a step back and saying "ah, let me design this quant algo to select the best stocks" -- and then succeeding -- I'd be impressed. I'd also know that it was learned from every quant that had AI double check their calculations/models/python.. but that's a different point.
Comment by lvspiff 7 days ago
This year So far all are beating the s&p % wise (only by <1% though) but the ai basket is doing the best or at least on par with my advisor and it’s getting to a point where the auto investment strategy of etrade at least isn’t worth it. Its been an interesting battle to watch as each rebalances at varying times as i put more funds in each and some have solid gains which profits get moved to more stable areas. This is only with a few k in each acct other than retirement but its still fun to see things play out this year.
In other words though im not surprised at all by the results. Ai isnt something to day trade with still but it is helpful in doing research for your desired risk exposure long term imo.
Comment by lisbbb 7 days ago
Comment by mvkel 7 days ago
Would have been better to have variants of each, locked to specific industries.
It also sounds like they were -forced- to make trades every day. Why? deciding not to trade is a good strategy too.
Comment by snapdeficit 7 days ago
Have the LLMS trade anything BUT tech stocks and see how they do.
That’s the real test.
EDIT: I remember this is probably before AmeriTrade offered options. I was calling in trades at 6:30AM PST to my broker while he probably laughed at me. But the point is the same: any doofus could make money buying tech stocks and holding for a few weeks. Companies were splitting constantly.
Comment by hoerzu 8 days ago
Comment by FrustratedMonky 7 days ago
This same kind of mentality happened pre-2008. People thought they were great at being day-traders, and had all kinds of algorithms that were 'beating the market'.
But it was just that the entire market was going up. They weren't doing anything special.
Once the market turned downward, that was when it took talent to stay even.
Show me these things beating a downward market.Comment by energy123 7 days ago
> an extensive empirical study across more than 70 models, revealing the Artificial Hivemind effect: pronounced intra- and inter-model homogenization
So the inter-model variety will be exeptionally low. Users of LLMs will intuitively know this already, of course.
Comment by throwaway422432 3 days ago
Grok often suggested shares that jumped significantly within the next few weeks. Wondering if it's access to Twitter gave it an advantage in predicting major upswings based on general sentiment.
Comment by aidenn0 7 days ago
Imagine a market where you can buy only two stocks:
Stock A goes up invariably 1% per month
Stock B goes up 1.5% per month with a 99% chance, but loses 99% of its value with a 1% chance.
Stock B has a 94% chance of beating stock A on a 6 month simulation, but only a 30% chance of beating stock A on a 10 year simulation.
Comment by rao-v 7 days ago
Expecting an LLM to magically beat efficient market theory is a bit silly.
Much more reasonable to see if it can incorporate information as well as the market does (to start)
Comment by morgengold 7 days ago
Comment by rcarmo 7 days ago
In short, I don’t think this study proves anything unless they gave the LLMs additional context besides the pure trading data (Bloomberg terminals have news for a reason—there’s typically a lot more context in he market than individual stock values or history).
Comment by keepamovin 7 days ago
Interesting how this research seems to tease out a truth traders have known for eons that picking stocks is all about having information maybe a little bit of asymmetric information due to good research not necessarily about all the analysis that can be done. (that’s important but information is king) because it’s a speculative market that’s collectively reacting to those kind of signals.
Comment by peterbonney 7 days ago
Comment by mlmonkey 8 days ago
Grok is constantly training and/or it has access to websearch internally.
You cannot backtest LLMs. You can only "live" test them going forward.
Comment by cheeseblubber 8 days ago
Comment by mlmonkey 8 days ago
Comment by luccabz 8 days ago
1. train with a cutoff date at ~2006
2. simulate information flow (financial data, news, earnings, ...) day by day
3. measure if any model predicts the 2008 collapse, how confident they are in the prediction and how far in advance
Comment by mempko 7 days ago
Comment by throwawayffffas 7 days ago
That's not going to work, these agents especially the larger ones, will have news about the companies embedded in their weights.
Comment by devilsbabe 7 days ago
> We were cautious to only run after each model’s training cutoff dates for the LLM models. That way we could be sure models couldn’t have memorized market outcomes.
Comment by client4 7 days ago
Comment by halzm 8 days ago
I more surprised that Gemini managed to lose 10%. I wish they actually mentioned what the models invested in and why.
Comment by Marsymars 7 days ago
That's a bold claim.
Comment by taylorlapeyre 8 days ago
Comment by btbuildem 7 days ago
Comment by culi 7 days ago
Comment by bmitc 7 days ago
Comment by throwawayffffas 7 days ago
Comment by bmitc 7 days ago
Comment by thedougd 7 days ago
Comment by mvkel 7 days ago
If the strategy is long, there might be alpha to be found. But day trading? No way.
Comment by oersted 7 days ago
There is of course the fact that physicists tend to be the best applied mathematicians, even if they don’t end up using any of their physics knowledge. And they generally had the reputation of “the smartest” people for the last century.
Anyway, such systems are complex and chaotic yes, but there are many ways of predicting aspects of them, like with fluid simulation to give a basic example. And I don’t get your point about weather, it is also recursive in the same way and reacting to its own reactions. Sure it is not reacting to predictions of itself, but that’s just a special kind of reaction, and patterns in others predictions can definitely be predicted accurately, perhaps not individually but in the aggregate.
Comment by mvkel 7 days ago
Yes, and it's priced in
> but that’s just a special kind of reaction
That's just arguing semantics. My point was that weather doesn't react to human predictions, explicitly
Comment by jerf 7 days ago
Less true than it used to be, with cloud seeding being an off-the-shelf technology now. Still largely true, but not entirely true anymore.
Comment by dehrmann 7 days ago
This isn't the best use case for LLMs without a lot of prompt engineering and chaining prompts together, and that's probably more insightful than running them LLMs head-to-head.
Comment by cedws 8 days ago
Comment by Genego 7 days ago
Comment by bwfan123 7 days ago
I am curious why re-reading incerto sharpens your bullshit sense. I have read a few in that series, but didnt see it as sharpening my bullshit sensor.
Comment by digitcatphd 8 days ago
Comment by hoerzu 8 days ago
Comment by dismalaf 8 days ago
Comment by Bender 8 days ago
[1] - https://www.youtube.com/watch?v=USKD3vPD6ZA [video][15 mins]
Comment by XenophileJKO 8 days ago
What you ask the model to do is super important. Just like writing or coding.. the default "behavior" is likely to be "average".. you need to very careful of what you are asking for.
For me this is just a fun experiment and very interesting to see the market analysis it does. I started with o3 and now I'm using 5.1 Thinking (set to max).
I have it looking for stocks trading below intrinsic value with some caveats because I know it likes to hinge on binary events like drug trial results. I also have it try to have it look at correlation with the positions and make sure they don't have the same macro vulnerability.
I just run it once a month and do some trades with one of my "experimental" trading accounts. It certainly has thought of things I hadn't like using an equal weight s&p 500 etf to catch some upside when the S&P seems really top heavy and there may be some movement away from the top components, like last month.
Comment by themafia 8 days ago
Comment by XenophileJKO 8 days ago
I was trying to not be "very" prescriptive. My initial impression was, if you don't tell it to look at intrinsic value, the model will look at meme or very common stocks too much. Alternatively specifying an investing persona would probably also move it out of that default behavior profile. You have to kind of tell it about what it cares about. This isn't necessarily about trying to maximize a strategy, it was more about learning what kinds of things would it focus on, what kind of analysis.
Comment by parpfish 8 days ago
It’d be great to see how they perform within particular sectors so it’s not just a case of betting big on tech while tech stocks are booming
Comment by IncreasePosts 7 days ago
Instead, maybe a better test would he give it 100 medium cap stocks, and it needs to continually balance its portfolio among those 100 stocks, and then test the performance.
Comment by natiman1000 7 days ago
Comment by diamond559 6 days ago
Comment by Glyptodon 7 days ago
Comment by apical_dendrite 8 days ago
Comment by RandomLensman 7 days ago
Comment by mikewarot 8 days ago
Comment by kqr 7 days ago
Comment by gwd 8 days ago
> Almost all the models had a tech-heavy portfolio which led them to do well. Gemini ended up in last place since it was the only one that had a large portfolio of non-tech stocks.
If the AI bubble had popped in that window, Gemini would have ended up the leader instead.
Comment by turtletontine 8 days ago
“Tech line go up forever” is not a viable model of the economy; you need an explanation of why it’s going up now, and why it might go down in the future. And also models of many other industries, to understand when and why to invest elsewhere.
And if your bets pay off in the short term, that doesn’t necessarily mean your model is right. You could have chosen the right stocks for the wrong reasons! Past performance doesn’t guarantee future performance.
Comment by gwd 7 days ago
Comment by Vegenoid 7 days ago
Comment by stockresearcher 7 days ago
I’ve glanced over some of it and really wonder why they seemed to focus on a small group of stocks.
Comment by XCSme 7 days ago
Comment by hsuduebc2 7 days ago
Comment by wowamit 7 days ago
Comment by refactor_master 7 days ago
Just riding a bubble up for 8 months with no consequences is not an indicator of anything.
Comment by Bombthecat 7 days ago
That tells me way more then "YOLO tech stocks"
Comment by krauses 7 days ago
Comment by jbritton 5 days ago
Comment by chongli 8 days ago
Comment by 10000truths 8 days ago
Comment by driverdan 7 days ago
Comment by machiaweliczny 7 days ago
Exactly. Makes no sense with models like grok. DeepSeek also likely has this leak as was trained later.
Comment by cramcgrab 7 days ago
Comment by itake 8 days ago
Did they make 10 calls per decision and then choose the majority? or did they just recreate the monkey picking stocks strategy?
Comment by ta12653421 7 days ago
This.
Thats also the reason why i still belive in "classic instruments" when configuring my trade app; the model wont give you the same entries on lets say 5 questions.
Comment by 1a527dd5 8 days ago
That has been the best way to get returns.
I setup a 212 account when I was looking to buy our first house. I bought in small tiny chunks of industry where I was comfortable and knowledgeable in. Over the years I worked up a nice portfolio.
Anyway, long story short. I forgot about the account, we moved in, got a dog, had children.
And then I logged in for the first time in ages, and to my shock. My returns were at 110%. I've done nothing. It's bizarre and perplexing.
Comment by jondwillis 8 days ago
Also N=1
Comment by delijati 8 days ago
Comment by lisbbb 7 days ago
The only way I have seen people outperform is by having insider information.
Comment by portly 7 days ago
LLMs are trained to predict the next word in a text. In what way, shape or form does that have anything to do with stock market prediction? Completely ridiculous AI bubble nonsense.
Comment by another_twist 7 days ago
Anyways this criticism is now dated given that modern day LLMs can solve unseen reasoning problems such as those found in the IMO.
It does have something to do with the stock market, since its about making hypotheses and trading based off that. However, I'd agree that making a proper trading AI here would require reasoning based fine tuning for stock market trading actions. Sort of like running GRPO taking market feedback as the reward. the article simply cant do that due to not having access to the underlying model weight.
Comment by bwfan123 7 days ago
Comment by lawlessone 8 days ago
Comment by iLoveOncall 8 days ago
People say it's not equivalent to actually trading though, and you shouldn't use it as a predictor of your actual trading performance, because you have a very different risk tolerance when risking your actual money.
Comment by ghaff 8 days ago
Comment by stuffn 7 days ago
Comment by pech0rin 7 days ago
Comment by deadbabe 8 days ago
Comment by fortran77 7 days ago
Comment by ta12653421 7 days ago
Comment by nurettin 7 days ago
Comment by 867-5309 7 days ago
Comment by dogmayor 8 days ago
Comment by elzbardico 7 days ago
Comment by aperture147 7 days ago
Comment by jacktheturtle 8 days ago
This is a really dumb measurement.
Comment by reformd 6 days ago
Comment by tiffani 8 days ago
Comment by theideaofcoffee 8 days ago
Comment by mrweasel 7 days ago
What could make this a bit more interesting is to tell the LLM to avoid the tech stocks, at least the largest ones. Then give it actual money, because your trades will affect the market.
Comment by apparent 8 days ago
Comment by koakuma-chan 8 days ago
Comment by scarmig 7 days ago
Comment by amelius 7 days ago
Also, it seems pretty stupid to use commodity tech like LLMs for this.
Comment by _alternator_ 8 days ago
Comment by darepublic 7 days ago
Comment by reactordev 7 days ago
Still, cool to see others in my niche hobby of finding the money printer.
Comment by vpribish 7 days ago
Comment by Frieren 7 days ago
Comment by chroma205 8 days ago
Stopped reading after “paper money”
Source: quant trader. paper trading does not incorporate market impact
Comment by zahlman 8 days ago
Comment by txg 8 days ago
Comment by tekno45 8 days ago
Comment by a13n 8 days ago
Market impact shouldn’t be considered when you’re talking about trading S&P stocks with $100k.
Comment by verdverm 8 days ago
Comment by theymademe 7 days ago
Comment by johnnienaked 6 days ago
Comment by frobisher 7 days ago
Comment by 867-5309 7 days ago
{kind=link}
Comment by andirk 8 days ago
Comment by petesergeant 8 days ago
Comment by regnull 7 days ago